Sommerpause – Zeit, als Fan die Beine ein wenig hochzulegen und sich von den Strapazen der nervenaufreibenden Saison zu erholen. Für mich bedeutet das, dass ich mich mit einem meiner Lieblingsthemen beschäftigen kann: Der Datenanalyse im Fußball (und Euch hierzu einen Longread liefere, der den Namen auch verdient hat). Das mag für viele ein staubtrockenes Thema sein. Für mich ist es aber nicht viel weniger als eine absolute Herzensangelegenheit. Das wird vermutlich daran liegen, dass ich meinen Beruf (Naturwissenschaftler) und meine Leidenschaft (Fußball) sehr gut unter dem Deckmantel Datenanalyse verbinden kann. Beides kann ich ein bisschen. Das reicht für eine fundierte Konzeptarbeit – oder aber ganz viel Halbwissen (dürft ihr nach Lesen des Textes selbst entscheiden). Ich bin jedenfalls davon überzeugt, dass wir in weniger als fünf Jahren in nahezu allen professionellen Fußballvereinen Positionen a la „Head of Data Analysis“ haben werden.
Aber warum ist das so? Welchen Mehrwert können Datenanalysen wirklich im Fußball liefern? Und, auch sehr wichtig, was können sie nicht liefern? Ich habe häufig das Gefühl, dass die Datenanalyse von einigen im Profibetrieb verteufelt wird, weil es „weiche“ Faktoren gibt, die eben nicht anhand von Daten bewertet werden können. Weil das Spiel „zu komplex“ sei, um es „durchzuanalysieren“. Das ist richtig. Im US-Sport (Basketball, Football, Baseball) ist das sehr viel simpler, da sich Standardsituation an Standardsituation reiht oder aber das Spielfeld und die Anzahl der Spieler geringer sind.
Sicher ist, dass tiefgehende Datenanalysen nie die klassische visuelle Analyse von Teams und Spielern ablösen werden. Aber darum geht es bei der Diskussion auch nicht. Manchmal habe ich das Gefühl, dass bei Verantwortlichen eine Art „Angst vor Neuerungen“ bei dem Thema vorhanden ist. Denn sicherlich werden viele der Schritte in einer Datenanalyse nicht von jedem im Klub nachvollzogen werden können. Und vermutlich haben viele auch die Sorge, dass Datenanalysen den von ihnen ausgeübten Job ablösen könnte. Aber tiefgehende Datenanalysen dienen nicht als Ersatz für die visuelle Bewertung von Spielern/Spielen/Spielzügen. Sie dienen vielmehr als Zusatz. Sie verbessern die Bewertung und machen das Bild dadurch runder, fundierter und, davon bin ich überzeugt, werden letztendlich dazu führen, dass Klubs sehr viel bessere Entscheidungen treffen können.
Ich habe mir ein paar Gedanken zum Thema Datenanalyse im Scouting gemacht, da es da bei einem offenen Sommertransferfenster auch immer viel zu bereden gibt, wie da die Abläufe sind. Das Scouting ist sicher der Bereich, in dem die intensive Nutzung von Daten den größten Effekt haben kann (neben der Spiel- und Standardanalyse und in medizinischen Abteilungen). Das liegt vor allem daran, dass die Verpflichtung und der Unterhalt von Spielern einer der Geldpools in Klubs ist, bei dem es am schwersten vorherzusagen ist, ob man für sein Geld auch das bekommt, was man „gekauft“ hat. Um besser einzuschätzen, ob Spieler wirklich die Skills haben, die das eigene Team weiterbringen, sind tiefgehende Datenanalysen eigentlich unabdingbar. Drei Gründe warum:
- Das visuelle Scouting ist voll von Fehlern (Biases). Hierzu interessante Beispiele (und hier der Text, in dem ich u.a. dazu gelesen habe):
Confirmation bias. Cristiano Ronaldo ist sicher ein toller Fußballer (menschlich ist der Typ, naja…). Als er damals das erste Mal für Real Madrid in der Champions League antrat, erzielte er gleich zwei Tore per Freistoß. Na klar, er ist halt ein Extra-Könner bei ruhenden Bällen. Da sind wir uns alle einig, da fast alle von uns bereits ein Freistoß-Tor von ihm gesehen haben. Aber ist er das wirklich – ein Extrakönner? Sicher kann er den Ball ganz gut treten, aber ein Extra-Könner ist er nicht. Seine Quote ist nicht viel mehr als mittelmäßig (vor allem im Vergleich zu Lionel Messi – später mehr dazu). Wie viele von uns denken aber, wenn der schmalzige Portugiese zum Freistoß antritt „Ouh, gefährlich, der kann das richtig gut.“, weil wir mal gesehen haben, dass er einen Freistoß (von seinen unglaublich vielen) versenkt hat? Und wie viele fühlen sich mit der These bestätigt, wenn er dann mal wieder einen trifft, obwohl er unzählige davor nicht versenkt hat?
Der confirmation bias sorgt bei uns dafür, dass unsere eigenen Erwartungen an ein Ereignis bestätigt werden („Ronaldo ist ein Freistoß-Gott“). Wir blenden die Informationen, die dabei nicht ins Bild passen (Vielzahl verschossener Freistöße) aus, damit unsere Erwartungen nicht wiederlegt werden.
Anchor bias. Noch so ein großes Problem im visuellen Scouting ist, dass es für eine Bewertung von Spielern immer eine Art Anker geben muss (sowas wie ein Richtwert, an dem sich ein Spieler messen lassen muss). Und das ist meist das erste Spiel oder die erste Aktion, die man von einem Spieler mitbekommt (im Fall von Ronaldo z.B. seine beiden Freistoß-Tore im ersten CL-Spiel für Madrid). In Verbindung mit dem confirmation bias führt das zu massiven Fehleinschätzungen, da wir Informationen ausblenden und womöglich den falschen Richtwert definieren. Das tun wir, weil es das menschliche Gehirn nicht anders kann.
Outcome bias. „Der FC St. Pauli hat diese Saison gruselig gespielt, denn er hat nur soundsoviele Punkte geholt.“ – der outcome bias ist wirklich am einfachsten zu erklären, aber auch meist einer der größten Fehler. Denn er geht vom Ergebnis aus. Da aber im Fußball nicht immer das bessere Team als Sieger vom Platz geht, hat der outcome bias Raum zur Entfaltung. Denn viele stellen sich die Frage: „Wir haben verloren – was war schlecht?“ oder „Wir haben gewonnen – was war gut?“ und bewerten Situationen aufgrund des Ergebnisses positiver oder negativer, obwohl zur Bewertung nicht das Ergebnis einzelner Spiele als maßgeblich gelten müsste.
Similarity bias. Wir Menschen sind schon ziemlich Ego-Tiere. Daher gibt es z.B. auch den similarity bias, aufgrund dessen wir Menschen, die uns ähnlich sind, besser bewerten als solche, die sich von uns unterscheiden. Ihr könnt Euch sicher vorstellen, dass der Effekt, den so ein Bias auf das Scouting haben kann, enorm ist.
Alle diese Fehleinschätzungen können durch Datenanalyse als Assistent zum visuellen Scouting verhindert werden. Und die Liste der Fehleinschätzungen kann nahezu beliebig verlängert werden (schaut mal hier den „Cognitive Bias Codex„ – und wenn ihr nur einen Link in diesem langen Text anklicken wollt, dann nehmt diesen bitte). Das ist keine Kritik an visuellen Scouts. Es ist halt einfach eine Art menschliche Fehleinschätzung, die da passiert und kann entsprechend nur von Menschen, nicht von Datenanalysen gemacht werden (wobei auch die Datenanalyse menschengemacht und daher nicht gänzlich frei von Fehleinschätzungen ist).
- Mithilfe von Datenanalyse kann die visuelle Arbeit von Scouts viel effektiver gemacht werden.
Viele PodcasthörerInnen werden sich bereits schon einmal mit der Frage befasst haben, wie zur Hölle man den ganzen Kram, den man gerne hören möchte auch hören kann. Das Abspielen in 1,5facher Geschwindigkeit ist für die meisten zwar eine Lösung, aber es geht doch einiges an Hörvergnügen flöten. Noch schwieriger wird es beim Scouting, denn Spiele in 1,5facher Geschwindigkeit sind sicher noch unerträglicher. Aber um die Aktionen von Spielern komplett zu erfassen bedarf es nun einmal visuelles Scouting. Dazu gibt es inzwischen WyScout und InStat, die von Spielern Videoschnipsel von allen möglichen Aktionen anbieten. Aber auch diese ganzen Aktionen müssen angeschaut und vor allem bewertet werden. Wenn nun im Vorwege eines solchen Scoutings bereits eine tiefgehende Datenanalyse stattfindet, dann reduziert sich die Zahl der Spieler, die visuell gescoutet werden müssen automatisch und steigert die Effektivität.
- Datenanalyse kostet einen Klub nicht mehr, sie kostet weniger.
Nehmen wir mal an, dass ein Spieler 250.000 € pro Saison verdient. Ich würde schätzen (sehr konservativ, also eher unterschätzt), dass das in etwa der Mittelwert der Spielergehälter in der 2.Liga ist. Wenn ein solcher Spieler also zu einem Klub kommt und einen Zwei- oder Drei-Jahresvertrag unterschreibt, dann ist das eine Entscheidung, die nicht mal eben durch 20 zusätzlich verkaufte Bier im Stadion oder zehn T-Shirts im Fanshop refinanziert werden kann. Und wir reden hier nur von einem einzigen Spieler. Pro Saison sind das inkl. Vertragsverlängerungen Summen, bei denen mir persönlich schnell übel wird. Eine ebenso vorsichtige Schätzung meinerseits geht von 100.000 € für die mögliche Sektion „Datenanalyse“ aus (ein „Head of“, zwei Informatik-Studierende, die die „Drecksarbeit“ machen und Kosten für die Daten selbst, die man bei verschiedenen Anbietern erwerben muss).
Ich bin zwar kein BWLer, aber wenn man mit tiefergehenden Datenanalysen nun die Trefferquote von Transfers nur um 5-10% hochschrauben kann (sicher kein unrealistisches Szenario), dann ist das ein lohnendes Investement und spart an anderer Stelle massiv Geld ein. Und gerade jetzt, wo aufgrund der Coronakrise die Einnahmen eben nicht mehr stetig wachsen und alle Klubs sparen müssen, werden sich in naher Zukunft wohl auch die Klubs durchsetzen, die im Scouting sehr effektiv arbeiten.

(c) Peter Boehmer
Wie müsste datengetriebenes Scouting aussehen, damit sich ein solches Investement lohnt?
Letztendlich fischen alle im selben Teich nach Spielern. Spätestens seit Plattformen wie InStat und vor allem WyScout Informationen und Daten zu nahezu jedem Spieler in jeder Profiliga der Welt bieten können, wird es nicht mehr so sein, dass Scouts im tiefen Südamerika, nach 1.910 Stunden Flugzeit, Übernachtungen in übelriechenden Hotels und über zahllose Kontakte einen Spieler zu sehen bekommen, den vorher noch nie jemand gescoutet hat.
Es geht also vielmehr darum, was man aus den Daten macht, die einem angeboten werden. Wenn man sich einfach auf die handelsüblichen Daten und Statistiken verlässt, dann wird man weiterhin mit allen anderen Klubs im selben Teich fischen. Und die Trefferquote wird sich entsprechend nicht groß unterscheiden bzw. ist komplett abhängig vom visuellen Scouting, welches ja nun voll von Fehlern ist. Wenn man die vorhandenen Daten jedoch in die Hand nimmt und daraus ein eigenes Modell, ein Profil, zugeschnitten auf die Bedürfnisse eines Klubs bzw. Teams erstellt, dann fischt man zwar immer noch im gleichen Teich nach Spielern, aber man hat eine andere (bessere?) Angel zur Verfügung. Und nur so wird man dann anhand von Daten auch Spieler entdecken, die vielleicht vorher unterm Radar geschwommen sind. Und nur dann wird man (auch preislich) auf dem Transfermarkt anders agieren können, als es alle anderen Angler am Teich tun.
Welche Daten werden angeboten?
Es gibt inzwischen unglaublich viele Anbieter im Fußball, die Daten aufbereiten und anbieten – und lobpreisen das Scouting damit zu vereinfachen. Die Plattformen InStat und vor allem WyScout vereinfachen das Scouting vor allem dahingehend, dass man sich Videoschnipsel von Spielern anschauen kann und die Skills von Spielern mit denen anderer vergleichen kann. Es gibt aber jede Menge Anbieter, die noch mehr eigene Datenanalysen anbieten. Ich stelle Euch mal ein paar vor:
Statsbomb
Der aktuelle „Poster-Boy“ der Datenaufbereitung und Visualisierung ist sicher Statsbomb und da besonders die sogenannten Radar-Charts. Diese zeigen die Skills von einzelnen Spielern, nach Ansprüchen je Positionen, im Vergleich zu allen anderen Spielern auf der gleichen Position an.

Grundsätzlich gilt bei der Betrachtung: Je mehr Farbe im Spiel ist, umso höher ist der spezielle Skill eines Spielers.
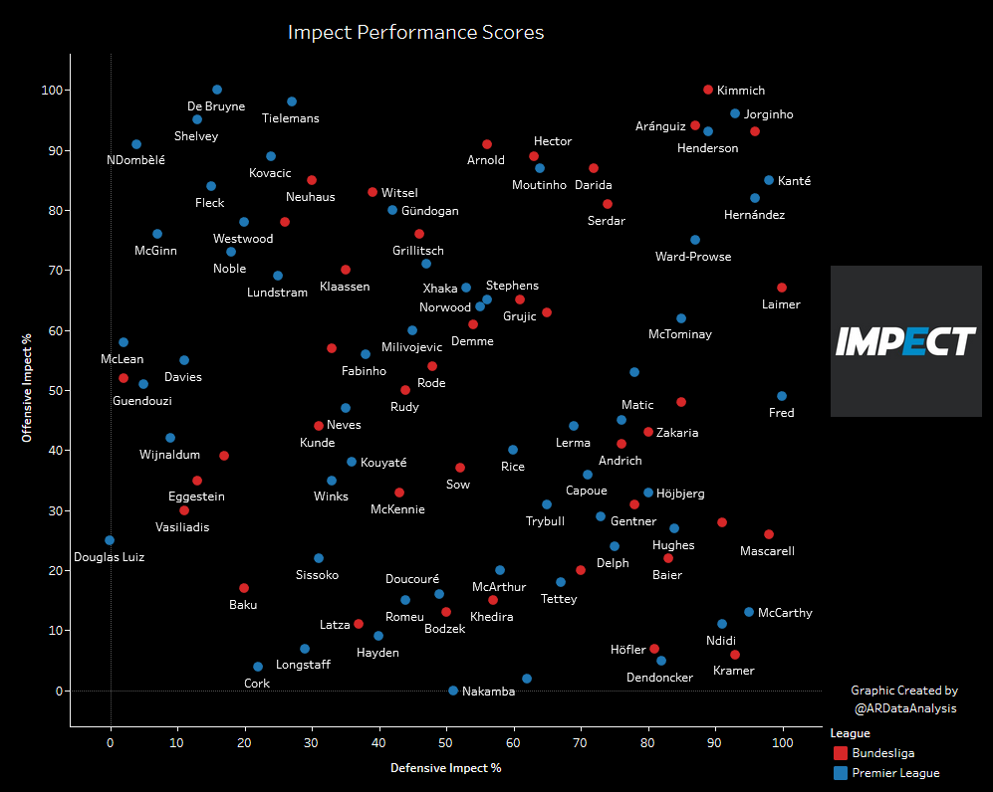
Der Vergleich von N’Golo Kantè und Kevin de Bruyne zeigt zum Beispiel, dass beide Spieler enorm stark im Mittelfeld sind, jedoch mit ganz unterschiedlichen Skills. Während de Bruyne mit Vorlagen und wichtigen Zuspielen die Maßstäbe in der Premier League setzt, tut Kantè das gleiche, aber mit defensiven Skills wie Tacklings, Ballgewinnen und im Pressing.
Auf diese Art und Weise kann doch relativ schnell erkannt werden, welche Spieler wirklich dauerhaft über gewisse Fähigkeiten verfügen. Spannend auch, dass die Fähigkeiten auch in ein Verhältnis von allen Ligen und nicht nur von der Liga gesetzt werden, in der die Spieler aktuell spielen. So zeigte auch der mal von mir via Twitter angefragte Radar-Chart zu Mats Møller Dæhli, dass dieser vor allem im Bereich „Ballgewinne durch Pressing“ international vorne mit dabei ist.

Die Daten in der Graphik zeigen die Werte im Vergleich zu allen Daten (auch international). In der Tabelle sind die Werte im Vergleich zur allen Spielern seiner Position der 2.Liga aufgezeigt. Ziemlich beeindruckend, sowohl die Leistung von Mats, aber auch die Darstellung von Statsbomb.
Keine Frage, die Daten von Statsbomb sind schon recht schick. Und viele Klubs arbeiten auch bereits mit Statsbomb im Scouting zusammen.
Goalimpact
Ein weiterer interessanter Anbieter von tiefergehenden Daten im Fußball ist Goalimpact. Wobei „tiefgehend“ hierbei eher der falsche Begfriff ist, es ist eher eine große Datenemenge. Denn der Entwicklung des Goalimpact liegt ein relativ simples, aber dadurch nahezu auf jede Popel-Liga und entsprechend jeden Spieler anwendbares Prinzip zugrunde: Basierend auf dem Ergebnis der Spiele und der Spieler auf dem Feld wird eine Art +/- Statistik angewendet. Zusätzlich gibt es immer noch auch gewisse Erwartungen an ein Spiel (vereinfacht: wenn Bayern München gegen den 1. FC Rumpelballhausen antritt, dann wird ein 1-0-Sieg anders gewichtet als wenn sie diesen gegen Real Madrid einfahren).
Das interessante an diesen Daten ist, dass die Statistik damit auch versucht off-ball actions der Spieler zu erfassen. Denn die meisten der angegebenen Statistiken beruhen auf Ball-Aktionen der Spieler, auf Zweikämpfen, Torschüssen, Pässen. Wie aber kann der Wert eines Spielers gewichtet werden, der Räume geschickt zustellt und so die Bälle gar nicht im Zweikampf gewinnen muss oder ein Spieler der durch einen klugen Laufweg eine Lücke in der gegnerischen Kette reißt und so den erfolgreichen Schnittstellenpass seines Mitspielers ermöglicht? Das ist ziemlich schwer zu bewerten.
Diesen Wert, den Spieler auf das Spiel des eigenen Teams haben, erfasst der Goalimpact allein schon dadurch, dass er den Erfolg eines Teams für alle Spieler eines Teams „gutschreibt“. Aber so einfach diese Statistik auch ist, es hat natürlich auch eine Menge Nachteile, wenn das reine Ergebnis als Faktor für die Leistung eines Teams herangezogen wird, da nicht jedes Team für seine Leistung auch in Form von Siegen belohnt wird. und natürlich ist auch bei positivem Ergebnis nicht immer die Leistung eines jeden einzelnen Spielers positiv zu bewerten. Aber der Goalimpact ist sicher eine Statistik, die für das Scouting gerade von jüngeren Spielern interessant ist, da das Modell auch immer eine Prognose der Entwicklung von Spielern angibt. Aber er ist eben als alleinige Statistik nicht aussagekräftig genug.
(Wer mehr über den Goalimpact erfahren möchte, kann sich gerne mal das Interview durchlesen, dass ich mal mit Thorsten Wittmütz von Goalimpact geführt habe).
Impect – Packing
Auch eine Art „Poster Boy“, wenngleich dieser vor allem von Mehmet Scholl bei der EM-Berichterstattung anno 2016 ganz schlecht dargestellt wurde, ist das „Packing“ der Firma Impect. Die Firma, gegründet von den beiden ehemaligen Spielern Jens Hegeler und Stefan Reinartz bietet eine andere Art der Auswertung von Pässen an: Es wird gezählt, wieviele Spieler durch Pässe „überspielt“ werden, also wieviele gegnerische Spieler nach einem erfolgreichen Pass weiter weg von ihrem eigenen Tor sind als der Ball als vorher. Es handelt sich hierbei um eine recht spezielle Statistik, aber diese ist von hoher Bedeutung, da sie damit die Passquote als solches ganz anders gewichten lässt.
Besonders anschaulich ist es als Beispiel: Wenn ich als Innenverteidiger konstant Quer- und Rückpässe spiele, dann habe ich sicher ne gute Passquote, aber bin ich dann wertvoller für das eigene Team im Vergleich zu einem Spieler, der häufiger vertikal spielt, damit die Wahrscheinlichkeit eigener Tore erhöht, aber auch mehr Fehlpässe produziert? Da beim Impect die Anzahl der überspielten Spieler gezählt wird, wird so der Qualität des vertikalen Passes mehr Gewicht verliehen (das Beispiel von Hummels und Subotic ist da sehr aufschlussreich).
American Soccer Analysis – g+
Wie viele von Euch wissen, ist die Nutzung von Daten im US-Sport sehr viel weiter fortgeschritten und akzeptiert, als im europäischen Fußball. Daher ist es auch nicht verwunderlich, dass der Blog American Soccer Analysis eine Art Vorreiter in der Datenanalyse im Fußball ist. Und pünktlich zur Coronapause präsentierten sie eine, wie ich finde, sehr interessante und aussagekräftige Metrik: goals added, kurz g+. Diese Metrik beruht auf Basis der von mir so geliebten expected goals. Mit dem Unterschied, dass bei dieser Metrik nicht nur den Torabschlüssen sondern jeder Aktion auf dem Platz eine Tor- und Gegentorwahrscheinlichkeit zugeordnet wird. So ist es möglich auszurechnen, wie sehr sich die eigene Torwahrscheinlichkeit und die des Gegners durch eine Aktion (z.B. gewonnener Zweikampf) verändert. Erhöht sich die eigene und/oder verringert sich die gegnerische Torwahrscheinlichkeit wird das dem entsprechenden Spieler, der die Aktion ausführte gutgeschrieben. Dadurch erfährt jeder Schuss, jeder Pass, jeder Zweikampf oder Ballgewinn/-verlust eine Gewichtung und Bewertung, die letztendlich die Bewertung aller Aktionen jedes einzelnen Spielers ermöglicht.
Diese Metrik ist recht fancy und hübsch ausgearbeitet, aber sie ist nicht so neu. Letztendlich ist sie sehr ähnlich zu der non-shot xG-Metrik, die auch versucht alle Aktionen fernab von Torschüssen und Torschussvorlagen zu bewerten. Und auch andere Anbieter haben ähnliche Metriken (Statsbomb z.B. xGBuildup, welches Pässe vor einem Torschuss bewertet oder xG Thread (xT) von Karun Singh (da wird das auch sehr schön mathematisch aufgedröselt) und, recht neu, der possession value, kurz PV, der Pässe bewertet und auch negative Werte ausspucken kann; meine Güte, es gibt sogar ein xG-Modell, welches nicht nur die Position des Torschusses sondern auch den Torschuss selbst mit einer Torwahrscheinlichkeit versieht, wird dann shot placement xG genannt). Aber es gibt auch aus dem Bereich der Sportwissenschaften einen ähnlichen Messwert der mit der schönen Wortschöpfung Dangerousity versehen wurde. Ihr seht, mit der Metrik expected Goals ist in den letzten Jahren unglaublich viel passiert.
Die Wachablösung der expected Goals als beste Metrik ever?
Und während ich vor mehr als zwei Jahren mal vollmündig ankündigte, dass expected goals in naher Zukunft die „normalen“ Torschuss-Statistiken in der medialen Berichterstattung ersetzen werden, tue ich an dieser Stelle gleiches, nur beziehe mich dabei auf goals added. Ich bin davon beeindruckt, wie aus der Metrik xG weitere Metriken geschaffen wurden. Von xG, über expected Assists (xA), hin zu tieferen Passketten (xG Thread, xG Buildup und PV) und mit Dangerousity hin zu der Bewertung der Aktion auf dem Feld bei jeder Aktion, die mit g+ & non-shot xG womöglich eine Art Vollendung findet. Ich halte die Aussagekraft von g+ im Scouting zwar für begrenzt, weil es eben eine allgemeine Bewertung und keine Bewertung der einzelnen Skills ist (was nicht bedeutet, dass man sie im Scouting nicht nutzen sollte), aber die Metrik ist recht gut verständlich und für eine grobe Einschätzung der Leistung von Spielern zigmal besser als die bisher präsentierten Laufdistanzen, Zweikampfwerte und Passquoten.
21st Club
Im Stile einer Beratungsagentur kommt 21st Club daher. Und die Beratungen, die sie anbieten, sind auch häufig sehr viel weiter gefasst, als der Blick auf die einzelnen Skills von einzelnen Spielern. Da geht es dann eher um Fragen wie: Welches ist aus wirtschaftlicher Sicht das beste Alter um Spieler zu kaufen/verkaufen? Wie sehen die Leistungs-Unterschiede der einzelnen Ligen aus? Kann ein Spieler aus Liga X auch die gleiche Performance in Liga Y zeigen? Welche Altersstruktur im Kader haben erfolgreiche Teams? Welcher Trainer passt zu einem Kader? (ich hoffe die letzte Frage wurde kürzlich beim FCSP laut gestellt)
Es handelt sich also nicht unbedingt um einen Anbieter von Daten sondern ein Unternehmen, welches, basierend auf Daten, eine Art Handlungsempfehlungen für längerfristige Kaderstrukturen etc. gibt. Im weitesten Sinne ist also auch 21st Club ein Anbieter, der für datengetriebens Scouting sehr interessant sein kann. Und ich kann allen Verantwortlichen von Fußballklubs die Lektüre dieser Artikel empfehlen.
How do strike rates in-front of goal differ cross-continents? The 21st Club exchange rate model predicts how impactful some of the league’s most prolific scorers would be should they move cross league. The latest in our #DidYouKnow series. pic.twitter.com/CqsTLVxsgR
— 21st Club (@21stClub) April 6, 2020
Global Soccer Network
Ziemlich nahe an das, was Klubs im Scouting benötigen, kommt aus meiner Sicht das was Global Soccer Network anbietet. Und zwar richtig nahe. Ich kenne die dahinterliegenden Daten nicht, auf deren Basis letztendlich der GSN-Index gebildet wird, aber genau so müsste jeder Klub im Scouting vorgehen (wenn auch nicht gleich so aufwändig, weniger würde bereits reichen, um sich von anderen Klubs signifikant abzuheben). Um die angebotenen Daten und auch die Ideen hinter sowas etwas besser zu verstehen, empfehle ich Euch wärmstens das Interview vom VfL Bochum Fan-Blog einsachtvieracht mit einem der Macher von Global Soccer Network.
Spannend finde ich persönlich vor allem, dass hier nicht nur die Skills der einzelnen Spieler bewertet werden sondern man auch schauen kann, ob der Spielstil des eigenen Teams mit dem von anderen Teams zusammenpasst und es daher für Spieler einfacher sein könnte, sich an das neue Team anzupassen. Oder aber auch, dass, wie es Statsbomb auch bereits mit seinen Daten macht, Spieler je nach Ansprüchen der einzelnen Positionen bewertet werden. Ein weiterer Schritt als Statsbomb ist wohl der, dass auch geschaut werden kann, ob die Skillsets der Spieler auch zu anderen Positionen passen. Und es gibt auch eine Prognose für die einzelnen Spieler. Inwiefern diese zutreffen, kann ich natürlich überhaupt nicht sagen, aber da steckt schon einige Denkarbeit und Datenanalyse dahinter, wenn ich das oben verlinkte Interview beachte. Wie gesagt, auf den ersten Blick, mehr Einblick in die Daten und Prozesse von Global Soccer Network habe ich nicht, erscheint das wie ein Scouting-Tool, welches Klubs wirklich weiterhelfen kann.
Das ist nur eine kleine Auswahl an Anbietern von Daten zur Verbesserung der Bewertung von Fußballern und es sind wohl die bekanntesten Player auf diesem Markt. Es gibt noch viele weitere und sicherlich wird auch der FCSP Woche für Woche Angebote für solche Produkte erhalten, bei den der Anbieter einem die ultimative Verbesserung des eigenen Scoutings verspricht. Für weniger Daten-affine Menschen ist es dort sicher schwierig den Überblick zu behalten und wertvolle von wertlosen Daten zu unterscheiden (diese Frage bekommt gleich einen eigenen Abschnitt im Text). Übrigens ist es häufig optaSports, die der Daten-Lieferant sind für die ganzen Metriken, Indexe und Prognosen die solche Anbieter liefern (aber es gibt auch einige Anbieter, die die Daten selbst produzieren).
Und ganz allgemein gilt bei der Nutzung solcher externer Datenanbieter auch, dass weiterhin alle im selben Teich und dann entsprechend auch mit der gleichen, sehr viel besseren Angel arbeiten. Um sich wirklich im Scouting abzuheben und auch wirklich die Daten so zu nutzen, dass sie perfekt auf die Ansprüche eines Klubs, eines Spielsystems passen, benötigt es hauseigene Datenanalysen, bestenfalls in Verbindung mit externen Datenanbietern.
Eine eigene Abteilung für Datenanalysen und eine Nutzung mehrerer Quellen der Daten ist übrigens auch deshalb sinnvoll, um die Definitionen der einzelnen Bewertungskriterien kritisch hinterfragen zu können. So hat sich zum Beispiel mal Florian Zenger von Clubfans United damit befasst, warum FCN-Spieler Hanno Behrens bei drei verschiedenen Daten-Anbietern zu drei doch recht unterschiedlichen Zweikampfquoten kommt. Diese Definitionen sollten daher grundsätzlich hinterfragt und bestenfalls selbst entwickelt werden, damit es eben nicht zu einer falschen Einschätzung kommt.
Wertvolle oder wertlose Daten?
Wenn man sich dazu entscheidet bei der Suche nach neuen Spielern auf Daten zu vertrauen, dann sollten es natürlich auch die richtigen bzw. aussagekräftigen Daten sein. Das Beispiel Cristiano Ronaldo und Freistöße eignet sich perfekt für diesen Abschnitt: Denn wow, er hat ganze 30 Tore im Dress von Real Madrid per Standard erzielt. Betrachtet man diesen Wert, so würde man klar behaupten, dass wir dringend versuchen sollten ihn zu verpflichten, wenn wir einen Standard-Spezialisten suchen. Zur Wahrheit gehört aber auch, dass Ronaldo 410 Freistöße im gleichen Zeitraum direkt auf das Tor getreten hat. W.O.W! Bleibt also eine Erfolgsquote von knapp über 7%, was auf einmal nicht mehr so richtig dolle für einen absoluten Standard-Spezialisten spricht. Denn die durchschnittliche Conversion rate von Freistößen liegt bei knapp 6%. Die der 150 besten in Europa sogar bei knapp 13% (alles hier nachzulesen). Cristiano Ronaldo ist also nur ganz leicht mehr als ein durchschnittlicher Freistoßschütze. Und das Beispiel von Hummels und Subotic mit dem Vergleich ihrer Passquoten und dem dazugehörigen Packing habe ich bereits weiter oben beschrieben.
Wenn man also Daten für die Evaluierung von Spielern nutzen will, dann ist es unglaublich wichtig zwischen wertvollen und wertlosen Daten zu unterscheiden und die Aussagekraft sämtlicher Daten zu bewerten.
Aber welche Daten sind denn nun wertvoll bzw. wertlos?
Da bin ich natürlich bei weitem nicht der erste, der sich diese Frage stellt und in vielen Verein wird ja bereits mit Datenanalysten gearbeitet oder aber es werden von Anbietern Daten genutzt. Ganz grundsätzlich ist es natürlich sinnvoll und absolut einleuchtend, wenn die Spieler anhand unterschiedlicher Kriterien je nach Positionen gescoutet werden (da ein Stürmer andere Skills als ein Verteidiger braucht). Entsprechend müsste sich jeder Verein im Scouting erst einmal die Frage stellen, welches die Kern-Skills von Spielern auf bestimmten Positionen sind, welche Skills in dem Fußball, den ein Team spielen möchte, überhaupt benötigt werden.
Ich versuche dieser Frage mal etwas genauer auf den Grund zu gehen indem ich mal aufliste, welche Daten aus meiner Sicht für das Spieler-Scouting relevant sind und in eine Datenanalyse einfließen müssten:
Allgemeine Faktoren
- Alter
Ganz allgemein muss ein Spieler ein Team natürlich besser machen. Entsprechend sollte das Alter eines Spielers bei dieser Frage nur eine geringe Rolle spielen. Aber aus ökonomischer Sicht und auch aus Sicht der Kaderentwicklung über Jahre spielt das Alter von Spielern eine enorm wichtige Rolle. Das Alter spielt nämlich allein schon bei der Frage nach dem Wiederverkaufswert eine Rolle. Und es muss sich natürlich auch die Frage gestellt werden, ob sich ein Spieler noch entwickeln kann und dadurch ggf. zu einem höheren Preis den Verein wieder verlässt. Und natürlich sollten Klubs immer versuchen, die Spieler genau dann zum Klub zu lotsen, bevor der Marktwert steigt. Hierbei handelt es sich um eine ganz allgemeine Frage: Wollen wir als Klub einen Spieler entwickeln und mit einem höheren Wert wieder veräußern oder brauchen wir gerade auf der vakanten Positionen einen Spieler der uns sofort weiterhelfen kann? Die Ideallösung ist natürlich beides zusammen: Ein Spieler, der weiterhilft, aber sich auch noch weiter entwickelt und sich dann später für höhere Aufgaben empfiehlt.
- Körpergröße
Ja, die Körpergröße ist wichtig, da man nur bedingt einen Innenverteidiger aufbieten sollte, der nur 1,82m misst, da dieser dann in Kopfballduellen unterlegen ist. Aber die Körpergröße ist dafür nicht entscheidend. Es ist muss eher eine Angabe zur Sprunghöhe sein, die bei der Suche nach den entsprechenden Spielern berücksichtigt wird (die kann anhand physiologischer Eigenschaften ausgerechnet werden). Warum ich gerade 1,82m genannt habe? Schaut Euch mal die Sprunghöhe an:

(imago images / via OneFootball)
- Geschwindigkeit
Ein ganz zentraler Skill. Und in vielen Medien wird auch immer wieder mit Maximalgeschwindigkeiten hantiert. Das ist so richtig wie falsch. Denn was sagen uns schon die Maximalgeschwindigkeiten, wenn es viel wichtigere Werte im Bereich der Geschwindigkeit gibt? Ich persönlich würde beim Scouting z.B. viel mehr darauf achten, was ein Spieler auf den ersten 5, 10 und 25 Metern leisten kann, wie gut er beschleunigt. Denn wie oft werden Spieler pro Spiel überhaupt ihre maximal abrufbare Geschwindigkeit erreichen (müssen)? Eher selten. Aber kurze Beschleunigungen sind oft gefragt und daher wichtig (übrigens ist auch die Anzahl der Sprints pro 90min ein wichtiger Parameter).
Wer privat „FIFA“ spielt kennt dies auch, denn unter dem Oberbegriff „Schnelligkeit“ ist „Beschleunigung“ einer der wichtigsten Unterpunkte bei den Spielern.
- Verletzungshistorie
Brauche ich sicherlich niemandem zu erklären, warum der leidgeprüfte Marc Hornschuh aktuell bei vielen Vereinen durch das Scouting-Raster fällt. Denn Verletzungen sind vermutlich in jedem Verein der größte Posten an Wertverlusten.
Entsprechend sollte im Scouting sehr genau auf eben jene Verletzungshistorie geschaut werden. Wie oft war ein Spieler verletzt? Welche Art von Verletzungen gab es? Hat ein Spieler einfach Pech gehabt? Oder steckt mehr dahinter, wie z.B. schlechtes Training, unprofessionelles Verhalten? Ich habe das mal in diesem Text etwas genauer ausgeführt.
- Marktwert
Ist eh klar, dass man als ambitionierter Zweitligist keine Zeit darauf verschwenden sollte, in seinen Scouting-Modellen Spieler zu haben, die zu einer Anfrage aus der zweiten Liga maximal ein mildes Lächeln hervorbringen. Entsprechend muss ein Scouting-Modell eine Art Obergrenze für Spieler haben, damit bei einem Modell nicht immer direkt die ersten 20 Spieler aussortiert werden müssen, da sie eh nicht in das Preis- und Gehaltsgefüge eines Vereins passen. Der Marktwert von Spielern könnte in einem Scouting-Modell als eine Art Filter genutzt werden, um die Kategorie an Spielern außen vor zu lassen, die einen aufgrund der Preise nicht interessieren.
- Goalimpact / GSN – Prognosen
Die beiden bereits erwähnten Unternehmen Global Soccer Network und Goalimpact sind auch (oder besonders) deswegen interessant, da sie eine Prognose zu der Entwicklung der einzelnen Speiler liefern. Und obwohl die Trefferquote dieser Prognosen sicherlich nicht ansatzweise das ist, was sich die Macher, aber auch die Nutzer erhoffen (die individuelle Entwicklung von Spielern hängt halt viel zu krass mit der Situation in den Klubs (Spielzeit, System, Trainer, Konkurrenz) zusammen und das lässt sich über Jahre für einzelne Spieler schlicht nicht vorhersagen), so sind sie doch interessant und sollten beim Scouting berücksichtigt werden. Denn diese Prognosen basieren ja nicht auf Blicken in Glaskugeln, sondern wurden auch mittels historischer Daten, also der bereits abgeschlossenen Entwicklung von Spielern, validiert und so ist davon auszugehen, dass die Trefferquote zwar nicht optimal ist, aber sie kann neben der Einschätzung von visuellen Scouts eine weitere wichtige Bewertung liefern.
Skill-Set
- Standards
Grundsätzlich sollte bei der Einschätzung von Spielern die Performance bei Standards gesondert betrachtet werden. Als Beispiel dient Philipp Hofmann vom KSC, der diese Saison zwar beachtliche 17 Tore erzielt hat, davon jedoch drei per Elfmeter und (mindestens – war ne kurze Recherche) fünf nach einer Ecke. Rechnet man die Tore nach Standard-Situationen heraus, dann bleiben zwar immer noch ehrenwerte neun Tore übrig, aber so richtig beeindruckend ist das dann nicht mehr, was aus dem Spiel heraus passierte für einen Stürmer, der die Saison komplett unverletzt spielte und meist als alleinige Spitze agierte.
Will sagen: Standard-Situationen können den spielerischen Wert eines Spielers auf der gesuchten Position etwas ungenauer erscheinen lassen, wenn man diese nicht gesondert betrachtet. Denn es ist ja auch eine Stärke des Spielers bei Standard-Situationen gut zu performen. Nur sollte das eben gesondert bewertet werden.
- Successful actions
Ganz unabhängig von der Position, die gesucht wird, sollte man die gesamten Skills, die für eine Position benötigt werden, im Ganzen betrachten. Wie hoch ist die Erfolgsquote aller Aktionen eines Spielers auf dem Feld? Seien es Pässe, Torabschlüsse, Zweikämpfe. InStat liefert zum Beispiel so eine Metrik.
Zusätzlich sollten auch die Metriken g+, Dangerousity und/oder non-shot xG beachtet werden, da sie auch bei der Angabe der erfolgreichen Aktionen helfen, aber noch einen weiteren Mehrwert bieten, denn diese Metriken beinhalten noch Aussagen dazu, wie sich durch die Aktionen der Spieler die eigene Torwahrscheinlichkeit (und die des Gegners) verändert. Hilft uns ein Spieler dabei unsere Torwahrscheinlichkeit zu erhöhen und/oder die des Gegners zu verringern? Das ist die absolut zentralste Frage, die man sich beim Scouting stellen sollte. Und da ist die Nutzung der genannten Metriken sicher hilfreich.
- Abschlüsse & Wege dahin
Besonders bei Offensivspielern sicher eines der wichtigsten Skill-Sets. Neben den real erzielten Toren und Torvorlagen sollten hier natürlich xG und xA, aber auch weitere Metriken beachtet werden. Wie oft fanden Flanken ihr Ziel? Wie sieht es bei secondary Assists aus? So wird von opta z.B. auch die Metrik chances created definiert, welche die Torschussvorlagen, aber auch die vorangegangenen Pässe zusammenfasst.
Bevor wir uns hier aber in Nebensächlichkeiten verlieren, möchte ich noch einmal auf die Wichtigkeit der xG/xA-Metriken bei der Bewertung der Performance von Spielern zu sprechen kommen: Es ist schlicht elementar für Offensivspieler, dass bei den Aktionen auch was rumkommt. Wenn der FCSP einen Außenbahnspieler verpflichtet, der in, sagen wir mal 50 Spielen ganze drei Torvorlagen und zwei Tore gemacht hat, dann sollte dieser Spieler in den Metriken xG und xA dringlichst aufgezeigt haben, dass da noch viel mehr möglich ist (ich habe da übrigens niemand spezielles im Sinn). Oder zumindest sollte ein solcher Spieler dann im Bereich secondary Assists/chances created ’ne absolute Ausnahmeerscheinung sein.
Oder aber es gibt kluge Köpfe, die erkennen, dass ein solcher Spieler viel mehr Potenzial hat (aber das ist ein anderes, ein gänzlich eigenes Thema, später mehr dazu).
Übrigens: expected Goals-Modelle können und sollten natürlich auch für die Bewertung von Defensivspielern genutzt werden. Mit dem Grundsatz „Je niedriger der xG-Wert des Gegners, umso besser die Defensivarbeit“ besteht zwar noch viel Raum für Fehlinterpretationen, aber im Ansatz kann die Metrik hierfür verwendet werden.
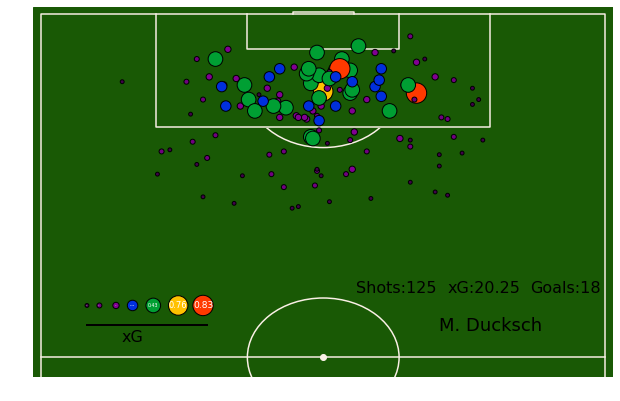
Erstellt habe ich die mal mit Daten von Stratabet (gibt es inzwischen nicht mehr), die damals noch Daten für Blogger frei zur Verfügung stellten. Hier seht ihr übrigens, dass Marvin Ducksch mit 18 Treffern zwar Top-Torschütze von Holstein Kiel in der Saison war, jedoch auch mit satten 125 Torschüssen, die insgesamt einen xG-Wert von über 20 ergaben, noch ein paar mehr Tore hätte erzielen dürfen.
- Arten von Pässen
Sicher einer der wichtigsten Skills bei der Bewertung von Fußballern, da ein erfolgreicher und guter Pass viele Komponenten vereint (gute Technik, Reaktionsgeschwindigkeit, Raumgefühl). Wir hatten das Beispiel der Passquote bereits mit Subotic und Hummels. Ich schreibe es auch hier noch einmal ganz deutlich: Die Passquote aller gespielten Pässe ist nicht ansatzweise aussagekräftig. Wenn ein Spieler nur mit Rück- und Querpässen und entsprechend wenig Risiko im Passspiel agiert, dann darf sich gerne Lothar Matthäus auf Sky über die tolle Passquote eines Spielers freuen und irgendwas von „Weltklasse“ faseln. Aber solange die Pässe nicht weiter unterteilt werden, sind sie für das Scouting gänzlich uninteressant.
Und es gibt unglaublich viele Wege, Pässe zu unterteilen, welches je nach Position sinnvoll ist. Für Aufbauspieler ist da natürlich das bereits erwähnte Packing aussagekräftig. Bei Statsbomb werden für Innenverteidiger auch immer „unpressured long balls“ als Metrik angegeben. Ähnlich zum American Football ist die Metrik progressive pass yards, die angibt wieviele yards an Raumgewinn ein Spieler mit seinen Pässen produziert hat (und da gibt es sicher auch Spieler, die eher für Raumverlust gesorgt haben).
Ganz andere Pass-Metriken sollten z.B. beim Scouting von offensiven Außenbahnspielern betrachtet werden: Beim Packing wird nicht nur der Spieler in die Wertung aufgenommen, der mit einem Pass gegnerische Spieler überspielt hat. Auch die Spieler, die den Pass angenommen haben, werden mitgezählt bzw. die Anzahl der Spieler, die mit ihrer Ballannahme überspielt wurden. Das Packing ermöglicht also auch in gewissem Maße eine Bewertung des Freilaufverhaltens von Offensiv-Spielern. Und während z.B. progressive pass yards bei Offensiv-Spielern eher eine untergeordnete Rolle spielen (da sie ja meist bereits vorne sind und dort die Pässe spielen) bekommt dort die Metrik Pässe im Offensivdrittel eine besondere Bedeutung. Zusätzlich müssen gerade bei Außenbahnspielern auch die Flanken als solche von anderen Pässen gesondert betrachtet werden.
Für zentrale Spieler, die für den Spielaufbau verantwortlich sind, sind dann z.B. Pässe mit denen Ketten überspielt werden interessant (bei WyScout heißen die z.B. smart passes).
Und natürlich sollte auch bei allen Pässen, sofern es die Analyse hergibt, bewertet werden unter welchen Druck welche Art von Pässen gespielt wird. Hier kann eine Analyse von Positionsdaten hilfreich sein, um herauszufinden, unter welchem Gegnerdruck ein Spieler während des Passes stand.
In ein Scouting-Modell sollte dann eine Art gewichtete Quote für die vielen eigens definierten Unterarten von Pässen eingehen (z.B. Nicht-Risiko-Pässe sind nicht so wertvoll wie Risiko-Pässe und erfolgreiche Pässe im Angriffsdrittel wertvoller als solche ohne Gegnerdruck im Aufbauspiel, etc.).
- Zweikämpfe
Klar, Zweikämpfe müssen auch bei der Betrachtung unterteilt werden. Handelt es sich um Defensiv- oder Offensiv-Zweikämpfe, ist es ein Boden- oder Luftzweikampf und wo auf dem Platz wurde der Zweikampf geführt? Auch hier gilt, dass die allgemein angegebene Zweikampfquote nicht so richtig viel Aussagekraft besitzt (aber aus meiner Sicht doch deutlich mehr als die allgemeine Passquote) und die Metrik besser wird, je mehr sie unterteilt wird. Und trotzdem sollte hier mit einer Quote gearbeitet werden. Spieler, die nur 30% ihrer Offensiv-Zweikämpfe gewinnen, sind vielleicht in der Offensive auch nicht hilfreich.
Zur Metrik „Zweikämpfe“ zähle ich auch Dribblings, die bei Offensiv-Spielern eine hohe Bedeutung haben. Besonders auf den Außenpositionen wird es auch zukünftig einen Fokus auf 1-gegen-1-Situationen geben. Und nur, wenn es Spieler schaffen eine bestimmte Anzahl an Dribblings erfolgreich zu gestalten, kann er auch wirklich hilfreich sein und das eigene Spiel verbessern.
- Ballgewinne / -verluste
Eine weitere zentrale Metrik sind Ballgewinne und -verluste. Hierbei ist besonders wichtig, dass sie in Relation zum Ballbesitz eines Teams betrachtet werden. Bei Statsbomb werden z.B. possession adjusted values für Zweikämpfe und Ballgewinne angegeben. Denn es ist sicher einleuchtend, dass ein Team mit viel Ballbesitz weniger Ballgewinne insgesamt zu verzeichnen hat und entsprechend die absolute Anzahl an Ballgewinnen von Spielern dadurch anders ist als bei Teams, die weniger Ballbesitz haben.
Bei der Bewertung von Ballgewinnen und -verlusten ist weiterhin auch die Position auf dem Spielfeld entscheidend (und natürlich der Gegnerdruck). Hat ein Stürmer viele Ballverluste in der gegnerischen Hälfte, weil er häufig allein gegen drei Gegenspieler agieren muss, ist das anders zu bewerten, als wenn einem Außenbahnspieler unbedrängt der Ball mehrfach verspringt.
- Index
Viele frei und nicht frei verfügbare Datenportale zu Spielern geben Indexe zur Stärke der Spieler an. Bei den frei verfügbaren werde ich sicherlich nicht die kicker-Durchschnittsnote erwähnen. aber es gibt z.B. whoscored und sofascore, die anhand von Daten einen Index für Spieler produzieren. Diese sind jedoch meist recht schlicht gehalten und ziehen in die Bewertung z.B. erzielte Tore überproportional mit ein.
Und da ich vor wenigen Wochen mal einen Blick in die Daten von InStat werfen konnte, habe ich auch den dort vorhandenen InStat-Index kennengelernt. Aber es gibt natürlich auch von WyScout und GSN so einen Index.
Wichtig bei der Nutzung: Wenn nicht klar ist, welche Kriterien wie genau für die Erstellung eines solchen Index genutzt werden, ist der Wert an sich zwar interessant, aber eben auch nicht die wichtigste Bewertungsgrundlage. Vor allem, wenn ein Klub einen eigenen Weg im Scouting gehen möchte, ist es ratsam sich nicht auf die für alle anderen Klubs ebenfalls verfügbaren Indexe der Anbieter zu verlassen.
Ein Scouting-Modell entwickeln
Nun haben wir eine ganze Reihe von Werten und Faktoren, die aus meiner Sicht im Scouting berücksichtigt werden müssen. Aber wenn man diese Werte alle einzeln betrachtet, wird man
1. völlig kirre, da man ob der Vielzahl von Faktoren ganz schnell den Überblick verliert und
2. nicht wirklich weiterkommen, da die Daten sich nicht einfach mal eben so zusammenrechnen lassen.
Welche Struktur brauchen die Daten also, damit man möglichst den Spieler damit erfasst, der einem Verein wirklich weiterhelfen kann? Und welche Struktur benötigt ein Verein, damit er sich im Scouting von anderen abhebt?
Machen wir es kurz: Ein Klub muss sein eigenes Scouting-Modell entwickeln. Ein Modell, das für jede gesuchte Position im Kader einen eigenen Index, gefüttert mit eigens definierten Ansprüchen, hervorbringt. Nur damit kann sich ein Klub wirklich nachhaltig von anderen Klubs abheben und eigene Wege im datengetriebenen Scouting beschreiten, da er sich nur durch ein eigenes Modell in seiner Bewertung von Spielern von anderen Klubs abhebt.
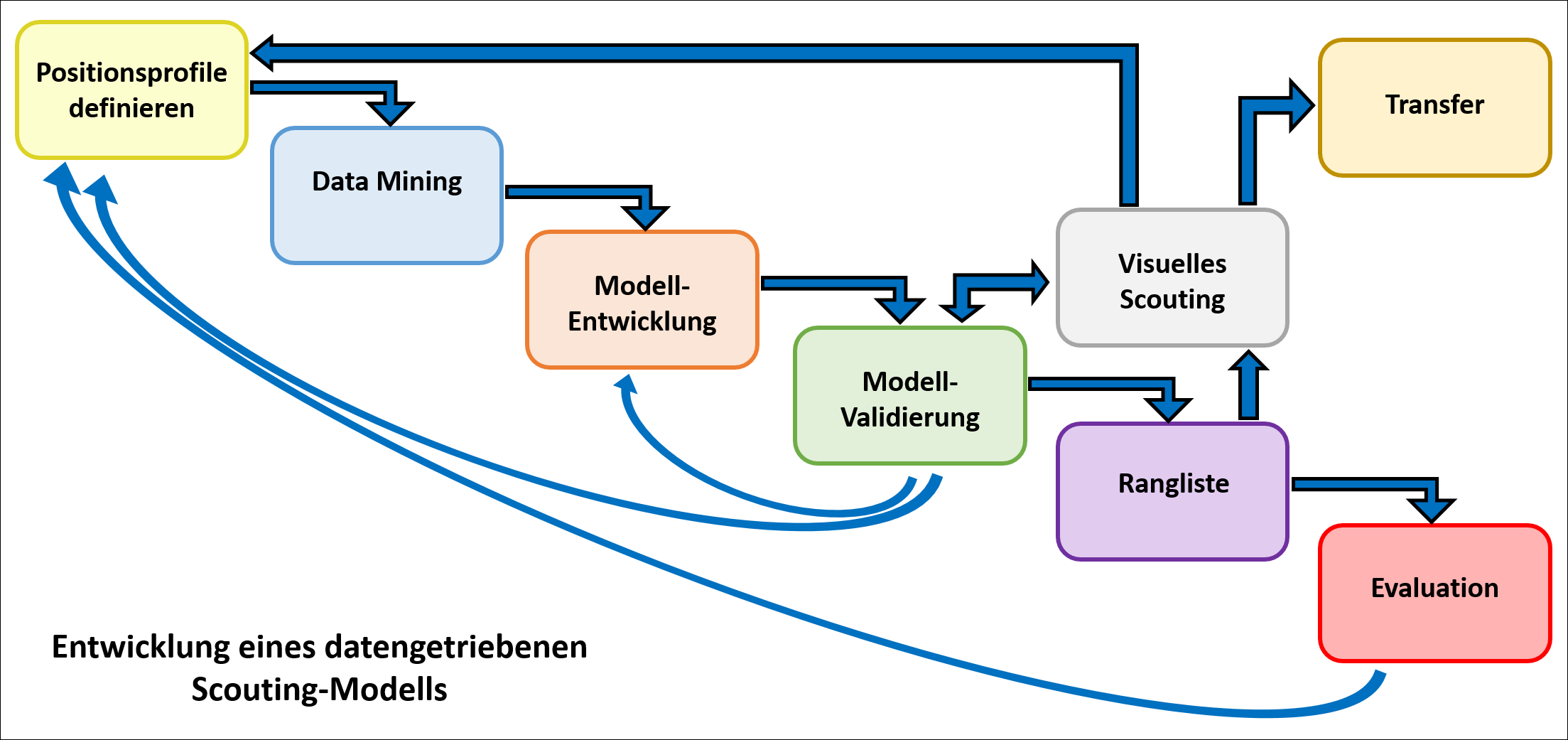
Wie entwickelt man aus den herausgearbeiteten wertvollen Daten nun ein Modell, welches in einem Verein zur Anwendung kommen kann? Es gibt natürlich auch bereits externe Anbieter, die sowas entwickelt haben – aber auch hier gilt: Wer anders sein möchte, muss sowas selbst erstellen, da sonst mit den gleichen Rahmenbedingungen im selben Teich gefischt wird. Zur Entwicklung eines klubeigenen Scouting-Modells ist ein Vorgehen in mehreren Schritten notwendig:

Schritt 1: Positionsprofile definieren
Ich habe bereits eine Reihe relevanter Daten für das Scouting hervorgehoben. Und dabei wurde auch schnell klar, dass es z.B. für einen Innenverteidiger erstmal unwichtig ist, wie hoch sein xG-Wert aus dem Spiel heraus ist. Viel wichtiger ist da natürlich sein Defensivverhalten (Boden- und Luftzweikämpfe, Anzahl an Klärungen/Ballgewinnen), sein Passspiel im Aufbau und so weiter.
Ein Klub sollte daher für jede einzelne Position im Kader ein Profil definieren, aus dem klar wird, welche Art von Daten für die entsprechende Position relevant sind und daher in ein Scouting-Modell mit einfließen sollten. Das ist Arbeit, die immer und immer wieder neu evaluiert werden muss, je nachdem, wie sehr sich die Ansprüche an einzelne Positionen oder an den Kader mit der Zeit verändern.
Schritt 2: Data Mining
Hat man erst einmal die Positionsprofile entwickelt, kommt der Schritt des Data Mining. Hierbei sollten sich Klubs zuerst die Frage stellen, ob sie die Daten selbständig erheben wollen (aus den Positionsdaten der einzelnen Spiele) oder ob sie diese von Daten-Anbietern sammeln.
Meine Meinung: Es bietet sich eine Mischung aus beiden Ansätzen an, da einige der Metriken, die für einen Klub interessant sind nicht „von der Stange“ zu bekommen sind. Wenn ein Klub Daten einkauft, sollte sich das nicht auf einen einzigen Anbieter beschränken. „Viel hilft viel“ muss hier das Credo lauten. Denn wie bereits das Beispiel mit den Zweikampfwerten gezeigt hat: Nicht jedes xG-Modell kommt zum gleichen Ergebnis, da z.B. bei einem Modell die Anzahl der gegnerischen Spieler zwischen Ball und Tor mit in die Berechnung einfließt, bei anderen Modellen diese Größe zwar fehlt, aber dort auch der Gegnerdruck (z.B. definiert als Anzahl der Spieler in bestimmten Radius um den auf das Tor schießenden Spieler) mit einbezogen wird. Daher ist es sinnvoll, möglichst viele verschiedene Daten-Quellen anzuzapfen, um ein möglichst genaues Bild zu bekommen.
Das Data Mining ist dann sicher auch der Punkt in der Entwicklung solcher Scouting-Modelle, bei dem viele „traditionelle“ Scouts und sportlich Verantwortliche im Fußball aussteigen. Es sind schlicht zu viele Daten. Bei einem einzigen Fußballspiel werden über 3 Millionen Positionsdaten erfasst. Und selbst die 2000-4000 Event-Daten pro Spiel (je nachdem welche Events erfasst werden), können schlicht nicht mehr gemütlich in eine Excel-Tabelle eingepflegt werden. Hier wird die Hilfe von Datenanalysten mit entsprechenden Programmier-Skills benötigt. Und ich kann aus eigener Erfahrung sagen, dass sich der Aufwand lohnt. Denn das schöne an so einer Datenanalyse in z.B. Python (my language of choice) ist, dass, sobald ein Skript erst einmal geschrieben wurde, die Prozesse wesentlich schneller laufen. Die Arbeit an einem Scouting-Modell mag an dieser Stelle zu Beginn die meiste Zeit fressen (wir reden hier nicht von Wochen sondern von Monaten), aber wenn die entsprechenden Skripte erst einmal geschrieben sind, dann nimmt das Data Mining erheblich weniger Zeit in Anspruch, da diese immer wieder verwendbar sind und selbst bei veränderten Positionsprofilen meist nur einer Feinjustierung bedürfen.
Schritt 3: Gewichtung der Daten
Hat ein Klub erstmal alle Daten zusammen, so muss eine Art Prioritäten-Liste erstellt werden. Welche Skills sind am wichtigsten? Worin muss ein Spieler definitiv gut sein? Gibt es Ausschlusskriterien? Die Gewichtung der für eine Position notwendigen Skills werden darüber entscheiden, ob ein solches Scouting-Modell zu einer allgemeinen Verbesserung des Scoutings in Klubs führen kann oder ob es sich eher um interessante, aber wenig aussagekräftige Zusatzinformationen zu Spielern handelt.
Entsprechend gründlich sollte an dieser Stelle gearbeitet werden. Der Vorteil, den ein eigens entwickeltes Scouting-Modell z.B. im Vergleich zu den Tools bei InStat bietet, ist vor allem, dass Spieler nicht nach Unterschreiten von gewissen Grenzwerten aus der Liste herausfliegen.
Ein Beispiel: Ich suche als Klub einen Spieler auf der Außenbahn, der vor allem viele Torschussvorlagen gibt. Entsprechend gut sollten seine Werte in den Bereichen expected Assists und bei der Flankengenauigkeit sein (um mal nur mit zwei Variablen in diesem Beispiel zu arbeiten – in Wahrheit sind es natürlich einige mehr). Bei InStat kann hierzu immer ein unterer Grenzwert definiert werden. Das führt dann aber dazu, dass Spieler, die den Grenzwert unterschreiten, komplett aus der Rangliste fliegen. Das wäre aber ziemlich doof, wenn es Spieler gibt, die allen anderen Ansprüchen mehr als genügen, nur eben nicht die erwünschte Quote bei Flanken erbringen. Arbeitet man jedoch mit der Gewichtung einzelner Skills, so wird ein Spieler zwar auch schlechter positioniert sein, wenn er eben nicht die gewünschte Flankengenauigkeit hat, aber nicht ganz aus der Rangliste fliegen. Ein wirklich wichtiger Unterschied, denn wenn es nur ein einziger Skill ist, der nicht die gewünschten Anforderungen erreicht, kann dieses Manko ausgeglichen werden, wenn ein Spieler in anderen Skills überragt. Es fliegt schlicht niemand aus der Wertung und somit kann auch niemand vom Radar verschwinden, der ins Raster passt, auch wenn einzelne Skills (noch) nicht so sind, wie gewünscht.
Um ein Modell zu erstellen, müssen die Werte dann auch noch aufeinander abgestimmt werden. Es ist wohl jedem klar, dass ein Wert von 20,3 bei der xG-Metrik nicht mal eben so mit einer Quote erfolgreich bestrittener Zweikämpfe in einen Topf geworfen werden kann. Entsprechend müssen die einzelnen Metriken mithilfe von Grenzwerten normiert werden, sodass am Ende einheitliche Zahlen ausgespuckt werden, die dann gewichtet werden können.
So ein Modell entwickelt sich natürlich nicht von heute auf morgen. Es wird Wochen bis Monate dauern bis aus den erhobenen und gesammelten Rohdaten ein gewichtetes Modell für jede einzelne Position entstanden ist. Aber auch hier gilt: Hat man erst einmal die Grundstruktur einer Rangliste für Spieler entwickelt, handelt es sich „nur noch“ um Feinjustierungen beim nächsten Schritt: Der Modell-Validierung.

(c) Peter Boehmer
Schritt 4: Modell-Validierung
Der erste Entwurf eines Scouting-Modells wird also eine Rangliste von Spielern auswerfen. Sind die besten Spieler dieser Rangliste dann auch wirklich die Spieler, die zu den besten auf ihrer Position zu zählen sind? Das wird in der ersten Version sicherlich nicht der Fall sein. Das Modell benötigt eine tiefgehende Validierung, um wirklich hilfreich zu sein. Für solch eine Validierung sind dann Experten nötig, die entsprechenden Input geben. Mit Experten meine ich Scouts, Fußballlehrer und ausgewiesene Kenner des Spiels und der Spieler. Der Klub sollte an dieser Stelle alles zusammenkratzen, was er an Fußballexpertise in seinen eigenen Reihen hat, um das datengetriebene Scouting-Modell zu einem wirkungsvollen Tool im Spieler-Scouting werden zu lassen.
Hierzu müssen die Experten eine Einschätzung der Rangliste abgeben. Decken sich die besten Spieler auf der Rangliste mit der Einschätzung der Experten? Falls nicht (und das wird in den ersten Versionen der Fall sein), warum taucht Spieler XYZ in dieser Rangliste soweit oben auf? Wurde eine Metrik falsch gewichtet? Wird die Bedeutung eines Skills generell überschätzt?
Nach dieser Art der Feedback-Runde müssten vermutlich die Positionsprofile und auch die Gewichtung der Daten überarbeitet werden. Danach ginge es in die nächste Runde. Und die nächste. Und idealerweise werden sich alle irgendwann fragen, was mit dem Modell falsch ist, da sich zwei Spieler, die es immer wieder in die Top10 schaffen, bisher noch gar nicht auf dem klubeigenem Scouting-Radar befunden haben. Und dann stellt man womöglich fest, dass diese Spieler bisher falsch bewertet wurden, sei es aufgrund von wenig Spielzeit oder weil die gesuchten Skills der Spieler bei visueller Betrachtung einfach nicht so zur Geltung kommen, wie es die Daten zeigen. Und wenn diese Spieler dann zusätzlich auch noch bei anderen Klubs bisher nicht auf dem Radar erscheinen sind, ja dann… Jackpot!
Zugegeben: Das ist der ideale Fall, der so nicht immer bei jedem Scouting-Modell für jede Position auftreten wird. Meist wird es eher darauf hinauslaufen, dass die Einschätzung des visuellen Scoutings durch die Datenanalyse eine Feinjustierung erfahren wird und die Einschätzung zu einem Spieler dadurch verbessert wird (was ja schon einen enormen Mehrwert schaffen würde).
Scouting-Modell ungleich Scouting-Modell
Ein eigens entwickeltes Scouting-Modell benötigt also Zeit. Aber wenn es erstmal entwickelt wurde, dann kann es aus meiner Sicht zu einem wirklich hilfreichem Tool in der Scouting-Abteilung von Klubs werden. Ich schreibe hier ganz bewusst, dass es sich um ein Tool handeln kann. So ein Modell würde das traditionelle Scouting nicht ersetzen sondern kann es signifikant verbessern.
Zu berücksichtigen ist auch, dass die Performance von Spielern je nach Liga gewichtet werden muss. Ich denke es wird allen einleuchten, dass ein Spieler aus der Regionalliga nicht sofort die gleiche Performance in der 2. Liga auf den Platz bringen wird. Entsprechend müssen auch die Skills allgemein noch gewichtet werden, je nachdem in welcher Liga diese gezeigt wurden.
Bei der Entwicklung, aber vor allem der Interpretation eines solchen Modells muss auf jeden Fall beachtet werden, was für ein Spieler verpflichtet werden soll. Benötigt ein Klub eine Soforthilfe, die anhand des vorhandenen Skill-Sets und weiterer Parameter dem Klub auf einer Position sofort verbessern kann? Oder ist ein Klub auf der Suche nach Spielern, die sich im Schatten arrivierter Kräfte entwickeln können? Nach Spielern, die noch nicht (dauerhaft) die notwendige Performance aufbieten können, aber ein hohes Potenzial haben? Der Idealfall wäre natürlich beides: Ein Spieler ist bereits eine echte Verstärkung, entwickelt sich aber auch noch weiter zu einem noch besseren Spieler.
Je nachdem, um welche Art von Spielergesuch es sich handelt, muss auch das Scouting-Modell ausgerichtet werden (es handelt sich dann natürlich um mehrere Modelle). Denn gerade bei jungen Spielern ist es völlig normal, dass diese nicht dauerhaft die beste Performance liefern, dass ihre Leistung auf dem Platz enorme Schwankungen aufweist. Entsprechend muss beim Scouting eher auf die Peak-Performance geachtet werden, als dass der Mittelwert oder Median als Größe in ein Modell einfließt. Ein Scouting-Modell kann diese Peak Performance zwar abbilden, aber die Einschätzung, ob ein Spieler sich auch verbessern kann und diese Peaks irgendwann konstant abrufen kann, ist dann natürlich wieder den Experten überlassen.
Die Frage, ob aus den Peaks auch eine konstante Performance werden kann, ist nicht viel weniger als der Kern, um den sich im Scouting von jungen Spielern alles dreht. Und sie ist unglaublich schwierig zu beantworten. Ich empfehle zu dieser Thematik ein YouTube-Video von Rasmus Ankersen. Ankersen ist einer der Köpfe bei den doch recht datengetriebenen Klubs Brentford FC und FC Midtylland.

(hier die Quelle der Graphik)
Wie würde das Scouting idealerweise laufen?
Zurück zum Thema: Es muss ja nicht gleich ein ganzes Bataillon an Datenanalysten sein und eine ganz eigene Abteilung im Scoutingbereich in Klubs gegründet werden. Bei vielen Klubs könnte das Scouting mithilfe von Datenanalysen sicher bereits signifikant verbessert werden, wenn sie jemanden hätten, der/die aus der Vielzahl an verfügbaren bzw. „einkaufbaren“ Daten nur diese herausfiltert, die wirklich für das Scouting im Klub relevant sind und eben Scouting-Modelle für einzelne Positionen entwickelt. Das verlangt eine grundlegende Ahnung von Fußball und natürlich mindestens eine gewisse Affinität zur Datenanalyse, damit große Datenmengen auch entsprechend gehändelt und so aufbereitet werden können, dass EntscheiderInnen damit auch arbeiten können.
Ich habe keine Ahnung, ob und wie intensiv mit dieser Art von Datenanalyse bereits in der 2.Liga gearbeitet wird (die Bataillone an Analysten gibt es aber z.B. bereits in eigentlichen allen Klubs der Premier League und auch in der 1.Liga arbeiten viele Klubs mit hauseigenen Daten-Analysten). Aus meiner Sicht ist die Arbeit mit Datenanalysen, allein schon bei den Summen, die Klubs in Spieler investieren, zwingend notwendig, da bereits ein finanziell verhältnismäßig kleiner Posten einen doch recht großen Beitrag zu erfolgreichem Scouting beitragen kann. Ein Versuch ein solches Modell zu entwickeln würde im Verhältnis zu den Kosten des Spielerkaders jedenfalls eher einen kleinen Fleck in der Jahresbilanz ausmachen. Entsprechend wäre meine banausige Einschätzung: Versuch macht klug!
Noch mehr lesen?
Wenn ihr Interesse an den Bereichen habt, in denen Datenanalyse im Fußball sinnvoll ist und bei Klubs bereits angewendet wird, dann schaut mal hier:
- Zum Beispiel eine super spannende Reportage über Ian Graham und seine Arbeit in Liverpool
- Sehr zu empfehlen sind auch immer die Texte, die von optasports veröffentlicht werden
- Eine allgemeine Beschreibung zur Nutzung von Daten bei Transfers findet ihr hier
- Wenn ihr mal wissen wollt, wie Daten bei opta erhoben werden und was damit in Zukunft möglich sein könnte, dann schaut mal hier
- Anwendung findet Datenanalyse z.B. beim Nachbarn bereits – und zwar im medizinischen Bereich
- Und ganz allgemein möchte ich allen das Buch „Matchplan: Die neue Fußballmatrix“ von Christoph Biermann zu dem Thema empfehlen
// Tim
Alle Beiträge beim MillernTon sind gratis. Wir freuen uns aber sehr, wenn Du uns unterstützt.
Das Verfassen von Kommentaren ist nur nach Registrierung möglich. Bitte bei Bedarf eine E-Mail mit Klarnamen und gewünschtem Username an Maik@MillernTon.de schicken.
MillernTon auf BlueSky // Mastodon // Facebook // Instagram // Threads // WhatsApp // YouTube




Vielen Dank für den umfassenden und sehr interessanten Einblick in die Thematik und vollste Zustimmung von mir hinsichtlich der Bedeutung von Daten beim Scouting und der Kaderentwicklung!
Vorweg: Bislang konnte ich noch nicht alles lesen, sondern hab es aus Zeitgründen am Ende überflogen.
Trotzdem möchte ich kurz einen Gedanken loswerden, den ich nicht gefunden, aber als sehr wichtig empfinde:
Puh, schwierig das was ich ausdrücken will, kurz, knackig und verständlich aufzuschreiben, aber ich versuche es. 🙂
Ein wichtiger Aspekt kann m.E. sein, die Daten der eigenen Spieler so zu erheben dass sie aussagekräftig aufgearbeitet werden können und auch für das Scouting genutzt werden (das hat natürlich auch weitere positive Aspekte…). Mit den daraus gewonnen Erkenntnissen über den eigenen Kader, kann dann eine „Angel“ gebaut werden, die aus dem Teich der Datenanbieter die Fische fängt, die den eigenen Kader (sukzessiv) verbessern.
Denn es geht ja nicht nur darum den besten Transfer in der BuLi zu machen, sondern eher darum den eigenen Kader sinnvoll und dazu möglichst preiswert zu verbessern…
…Bewertungen ergeben ja erst Sinn, wenn es nen Vergleichswert gibt 😉
Aufgrund der rasanten Entwicklung sollte wohl auch darauf geachtet werden, dass die Basis möglichst flexibel bleibt. Eigene Modelle erweiter- und anpassbar bleiben.
Ist echt ein Riesenfeld, dass super interessant ist! 🙂
Ja klar beinhaltet ein Scouting-Modell, welches nach Spielern sucht, die zum FCSP passen auch die Rückfrage, welche Spieler zum eigenen Kader passen. Dieser Vergleichswert muss bereits bei den zu erstellenden Positionsprofilen erschaffen werden und immer wieder neu hinterfragt werden.
…beim nochmaligen Lesen meines Beitrages lese ich in meinem „Beitrag“ zu wenig Demut heraus.
Hab mich mit dem Thema natürlich nicht so ausgiebig beschäftigt und bin nur ein interessierter Leser, der von aussen seinen schnellgedachten und seinen wenig euphorisierten Senf dazugibt (hab ja noch nicht mal alles gelesen!). Einen Senf, der wahrscheinlich schon bedacht wurde. Es kam mir halt nur sofort in den Sinn, mußte raus. Wollte das Thema halt mit dieser, äh, vorschnellen Äußerung von Gedanken unterstützen *verschämt wegguck*
Vielen Dank Tim, dass du meine Wochenendplanungen über den Haufen geworfen hast.
Nun also erstmal Scouting und dann Saisonrückblick Statistiken. ?
Werde mich erst mal durch die zahlreichen verlinkten Artikel wühlen. War doch das eine oder andere Neuland dabei.
???
P. S. Was sagt denn eigentlich Herr Sandmann dazu?
Tut mir leid, dass ich dein Wochenende nun auf den Kopf gestellt habe 😉
Hi Tim,
Sehr cooler Text. Danke sehr!
Was ich super spannend finden wueder waere, mehr zum Thema Bias zu lesen–angewendet darauf wie Spauli Fans und Medien betsimmte Spieler, Trainer oder Spoirtchesf wahrnehmen. Waere sicherlich kontrovers–aber koennte auch sehr hilfreich sein um fuer uns selsbt mehr Refletion zu entwickeln.
Zum Thema Data Science:
Es gibt eine ganze Reihe von Studien die zeigen, dass Technologien in Organisation nur dann effektiv eingesetzt werden, wenn sie mit der Organisationsstruktur und -praxis im Einklang stehen.
Fuer den FCSP stellen sich da mehrere Fragen:
(1) Ist es besser die Data Sceince Kompetenz regelmaessig von aussen einzukaufen (von einer ‚festen freien‘ Beratungsfirma, die fuer mehrere Vereine arbeitet) anstatt jemanden einzustellen (der eventuell nach einer bestimmten Zeit nicht ,mehr „up to date“ ist–denk mal an einige IT Experten in Organisationen)?
(2) Wo wuerde man eine solche Stlle ansiedeln? Trainerstab? Sportdirektor? (Was ist wenn der neue Trainer seinen egenen Analysten will?) Vertrieb/Marketingabteilung? (Aus meiner Sicht koennte der FCSP MINDESTENS GENAUSO davon profitieren Data Science im Marketing/Vertrieb einzseten wie im Profibereich)
Aus meiner Sicht waere es das beste wenn der neue Vize-Praesident eine gewisse Expertise im Bereich Data Science mitbringen wuerde. Der/die koennte dann als interner Experte agieren, und Trainer/SportDi/Marketing dabei unterstuetzen, zu entscheiden welche externen Data Science Tools/Berater sie einsetzen sollten.
HH ist Braun weiss,
Zet
Hi Zet,
ja, das sind sicher interessante Ansatzpunkte – war z.B. Chris Nöthe wirklich so lauffaul, wie ihm dauerhaft nachgesagt wurde?
Und ja, die Frage, ob es besser wäre jemanden von außen als Art Berater zu holen oder jemanden einzustellen, hat mich auch beschäftigt. Ich bin der Meinung, dass es eher hilfreich ist, wenn der Klub sich selbst jemanden ranholt, da die Strukturen teils über Monate/Jahre wachsen müssen, damit Data Science ein effektives Tool wird (was es aus meiner Sichtr defintiv werden kann, wenn sich ein Klub traut diesen Schritt zu gehen).
Ok. Wenn Du aber jemanden einstellen willst, wie kannst Du sicherstellen, dass die neue Expertise „instituionalisiert“ wird–also auch genutzt wird und nicht von Trainer/SpoDi ignoriert wird?
Deswegen ja meine Idee mit dem Vizepraesidenten, der das Thema dauehaft pushen koennte–und waere (erstmal) auch ohne Zusatzkosten, zu Zeiten der Corona Krise sicherlich auch bedenkenswert. 🙂
Ja, es ist natürlich ganz grundsätzlich ratsam, dass in (personal-)verantwortlichen Positionen Menschen sitzen, die da auch dauerhaft so etwas vorantreiben.
Danke, echt interessant!
Gibt es auch ein Analyse Tool für die Sozialkompetenz des Spielers?
– Passt er zum Verein?
– Passt er zu den Mitspielern?
– Verhalten auf und neben dem Platz?
– Lebensstil, Trainingsfleiß, Teamfähigkeit?
Das ist alles mindestens so wichtig wie die Fachkompetenz!
Jupp, viele Klubs (vornehmlich aus der Premier League) erarbeiten komplette Psychogramme von Spielern. Aber da ist natürlich auch sehr viel mehr Geld dahinter.
Danke für diesen sehr schönen Text. Für mich wäre das ein sehr guter Schritt in die richtige Richtung. Wie schon in den Kommentaren angemerkt, müsste man die Daten neben „hard“ Skills auch um „soft“ Skills irgendwann erweitern. Es ist ja nicht nur ein Vorurteil gegenüber Spielern, aber man sieht ja auch immer wieder, dass Spieler die sich sehr mit dem Verein identifizieren sehr gute Leistungen bringen (siehe Leo oder James diese Saison, bzw. Team von den dritten in die erste Liga).
Der nächste Schritt, wenn man dann ordentliche Daten hat wäre eine vernünftige Automatisierung. Wenn man dann in Richtung Neuronale Netze/ Deep Learning geht, braucht man halt aber auch schon sehr viele und gute Daten, sonst hat man wieder ein ganz anderes Bias Problem. Wenn man dies aber schafft hätte man schon halb gewonnen, was Vorhersagen zu Spielern auf einzelnen Positionen angeht. Hierbei müsste man idealerweise auch noch eigene Modelle anderer Teams aufbauen, mit deren Transfers, um damit seine eigenen Vorhersagen zu verbessern. So jetzt genug weiter rumgesponnen. Wie gesagt, wäre ein sehr guter erster Schritt und ich glaube, man sollte dort interne Expertise aufbauen. Auch wenn dieses durch Bruttolöhne leider bestimmt mehr als die 100k kostet. Bis man weiter gen Automatisierung kommt, werden leider bestimmt noch Jahre vergehen.
Gerade maschinelles Learning ist aus meiner Sicht quasi die Lösung, um Personalkosten in Grenzen zu halten.
Hallo Tim,
der Artikel ist mal wieder super! Was ich zusätzlich zum Scouting.-Aspekt interessant und lohnenswert finden würde, wäre eine Anwendung auf den eigenen Kader – nicht nur im Sinne der Trainingsbeobachtung, sondern auch im Sinne eines Benchmarking. Ist der Kader wirklich nicht zweitligareif, wie manche sagen, oder liegt es an Motivation/Aufstellung der Spieler bzw. einem System, das andere Tugenden fordert und erfordert? Das ist nicht ganz so einfach, wie es klingt, denn um so ein Modell zu entwickeln, muss man natürlich dann auch die Gegenproben mit Falsch-Positiven und Falsch-Negativen-Kontrollen machen. Trotzdem wird man dadurch sicher nicht dümmer und die oft unterschätzten Sportdirektoren waren am Ende wichtiger für den Erfolg der Mannschaft als die Trainer, denen der Erfolg viel schneller zugeschrieben wurde.
Beste Grüße
Jan
Moin Jan,
klar, allein schon um zu analysieren welche Positionen neu oder anders besetzt werden müssen, sollte eine solche Analyse durchgeführt werden.
Und einfach ist das alles nicht. Aber ich bin fest davon überzeugt, dass es sich absolut lohnt.